什麼是B+ tree
Tree是資料結構或演算法一定會講到的主題之一,大學的時候最常教的Tree大概是二元搜尋樹,那B+ tree跟二元搜尋樹哪裡不一樣呢?
B+ tree的特點是,資料有序排序,而且搜尋時間穩定
也因為這樣,常用於磁碟等大資料儲存系統,還有用在許多關聯式資料庫的索引中,如MySQL、PostgreSQL、MongoDB等
Binary search tree(BTS)
來複習一下Binary search tree的規則吧~
- 每個節點可以有左、右子節點
- 每個節點可以有0 - 2個子節點
- 左節點 < 根節點 < 右節點
- 任意節點的左、右子樹也分別為BTS
上圖是一棵平衡的BTS。假設現在要找出19:
- 19 < 50,往左邊找
- 19 > 17,往右邊找
- 19 < 23,往左邊找 在這棵樹裡面找19,硬碟總共I/O 3次 也就是說,最差的情況下,硬碟的I/O次數跟樹的高度一樣
B tree
等一下,標題不是在講B+ tree嗎?因為了解BTS和B tree之後,可以更了解B+ tree的特點,也就明白為什麼資料庫的索引選擇使用它
講B tree之前,先明確一個名詞:order,指的是一個節點最多可以擁有的子節點數量(以下以m表示)
下面是B tree的規則&特點: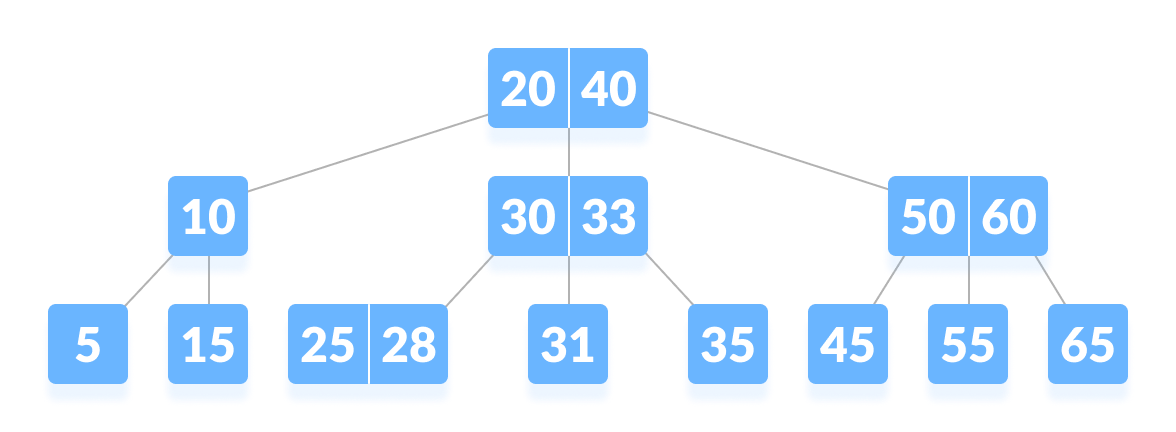
- 每個節點的子節點數量
- 2 ≦ root ≦ m
- ⌈m / 2⌉ ≦ internal ≦ m
- key數量 = m - 1
- 一個節點的key升序排序
- 所有葉節點出現在同一個水平上
- Self-balancing
說明:
看看上圖的樹,假設m = 3,那所有節點最多有2個key
拿中間的30|33節點來說,這個節點有2個key(30, 33),3個子節點(25|28, 31, 35) ,並且升序排序30<33 而且葉節點在同一個水平
Self-balancing
中文是「自平衡」,指的是在對樹執行插入和刪除操作時,自動保持高度盡可能小
也因為這樣,B tree相較二元樹的優勢是,在相同資料數量的情況,高度更低
高度更低,代表硬碟I/O的次數更少
舉個例子,在上圖的樹中尋找25:
- 20 < 25 < 40,往中間找
- 25 < 30,往左邊找
- 找到25
這棵樹總共有16個key,可以想像,相同的16筆資料畫成二元樹,搜尋要花多久時間
B tree的插入操作
這段是筆記,只想看原理的人可以跳過
例子一:
設m = 4,就是一個節點最多3個key
左半部分我們看到,這裡有一個根節點,10 20 30。現在我要加入一個40
但是一個節點最多3個key,已經滿了。所以從中間打斷,把20提出來當根,10和30分別為左右節點,再把40放進去
例子二:
一樣設m = 4
左半部分我們看到一棵樹,現在我要加一個70進去
但又不能放到右節點,因為已經滿了
這時把右節點從中間打斷,50提上去在根節點,然後把40和60變成子節點,這時就有三個子節點了,再把70放進去
B tree的刪除操作
例子一:
例子二:
例子三:
例子四:
B+ tree
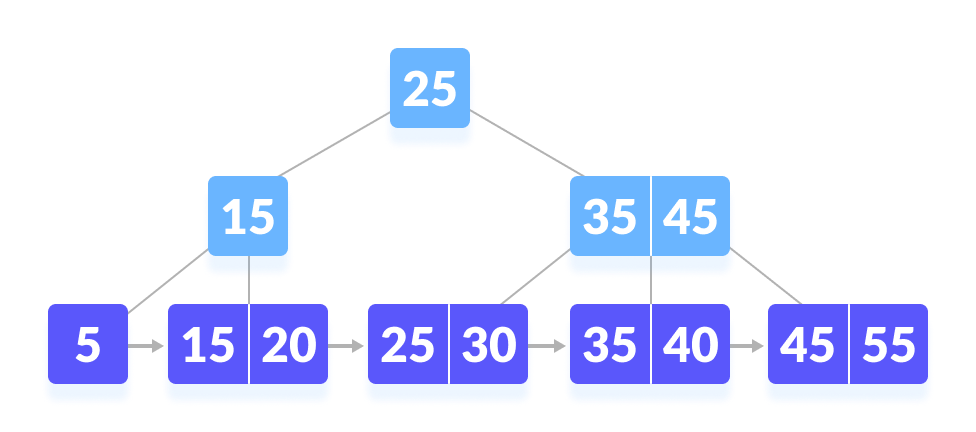
- 每個葉節點以Singly linked list 或 Doubly linked list 鏈結在一起
- 中間節點的key也會出現在葉節點
- B tree的資料存在每個節點,B+ tree的資料存在葉節點
從這些規則可以得出,每個節點的key大小長這樣:
B+ tree的優勢
B tree和B+ tree的區別之一在於,B tree的資料存在每個節點,B+ tree的資料存在葉節點
B tree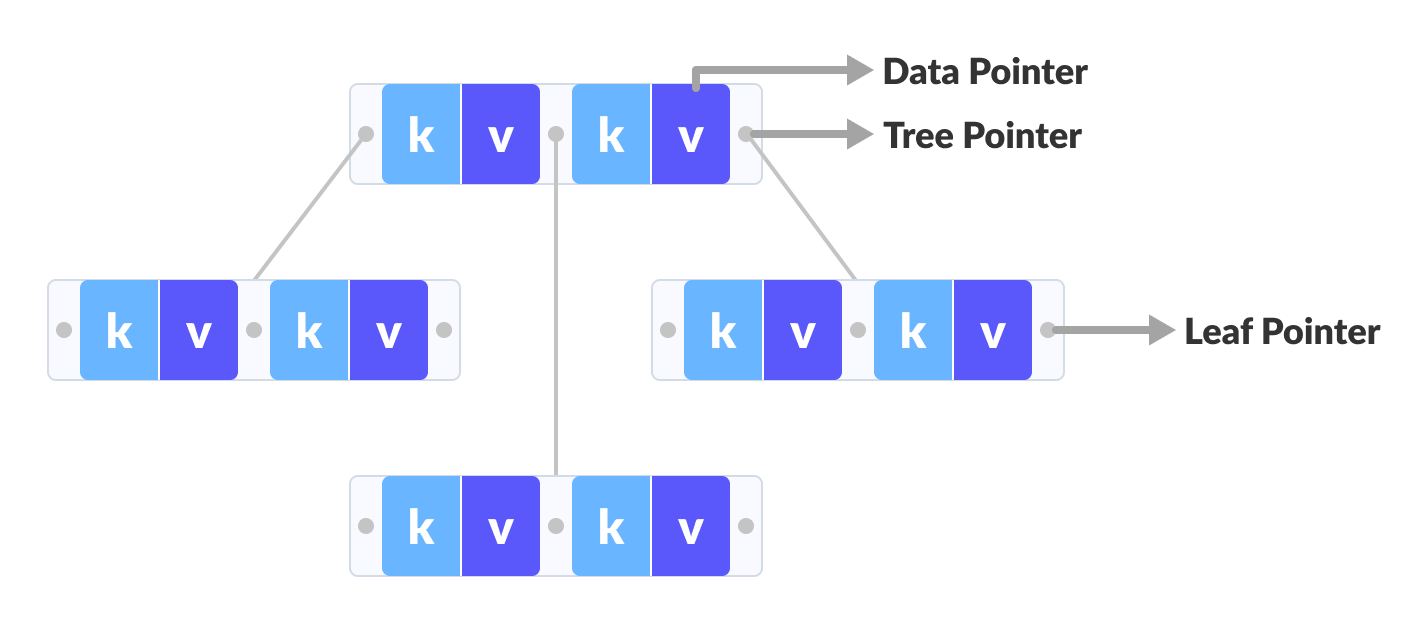
B+ tree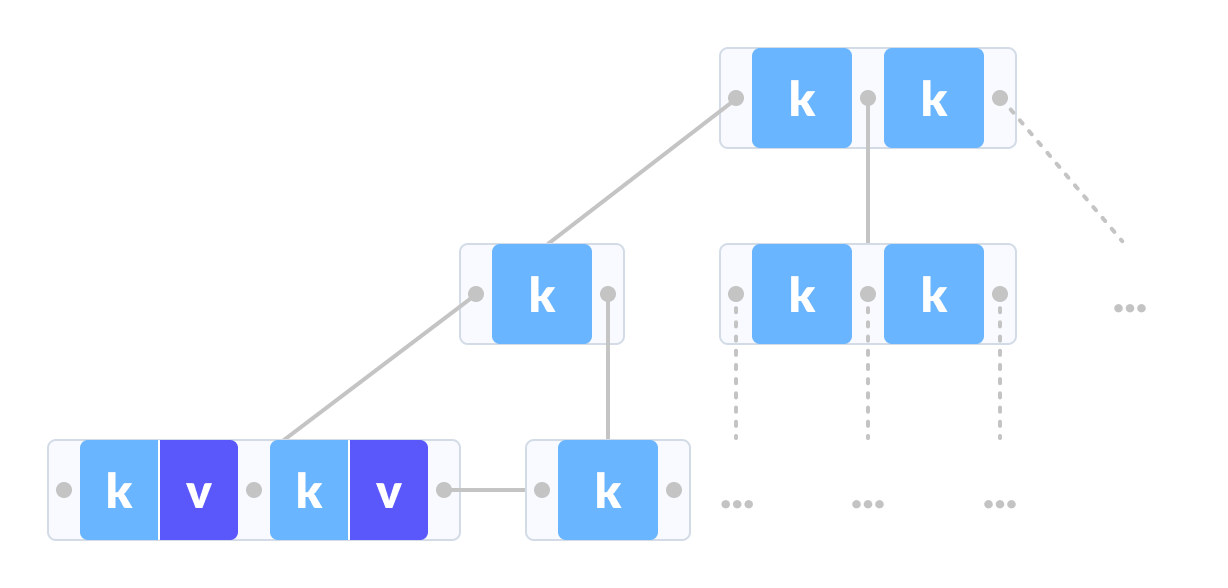
只有葉節點有資料,因此相同的大小的節點,B+ tree的key可以塞更多。也就是說同樣的資料量,B+ tree的高度更矮
B tree最好的情況是找到根節點,最壞的情況是找到葉節點,相較之下B+ tree更穩定
另一個優勢是,B+ tree的範圍查找更方便
前面有提到,B+ tree的每個葉節點以Singly linked list 或 Doubly linked list 鏈結在一起。正是如此範圍查找更方便
B tree
B+ tree
舉個例子,上面兩棵樹中我想找20 ~ 40的資料
B tree用中序遍歷查找,順序是20 15 25 30 35 40
B+ tree因為有link,所以找到20以後開始往兄弟找,順序是20 25 30 35 40,比B tree快很多!
B+ tree的插入操作
這段是筆記,只想看原理的人可以跳過
B+ tree的刪除操作
範例一:
範例二:
註:這棵樹的中序遍歷為10 20 30 40
範例三:
註:這棵樹的中序遍歷為10 20 30 40 50
總結三種tree的比較
| BTS | B tree | B+ tree | |
|---|---|---|---|
| 優點 | 在記憶體內搜尋速度快 | 硬碟I/O次數少 | 相較B tree,硬碟I/O次數少,範圍查詢快 |
| 缺點 | 應用在硬碟會有大量I/O | 插入、刪除節點速度慢,且範圍查詢使用中序遍歷 | 插入、刪除節點速度慢,且佔用空間大 |
| 應用 | Unix kernel管理virtual memory areas | 資料庫、檔案系統 | DBMS索引 |
B+ tree在資料庫索引的應用
MySQL InnoDB的Index
MySQL InnoDB採用了B+ tree來處理兩種索引,分別是:
- Clustered index:一個table只有一個clustered index,也就是PK。每個key都是PK,葉節點儲存這個record的資料
- Secondary index:除了PK其他索引都是secondary index。key是索引的欄位,葉節點儲存PK的資料

MySQL MyISAM的Index
與InnoDB不同的是,在MyISAM,無論Clustered index還是Secondary index,葉節點都是儲存record資料的位址
題外話:MySQL 8.0以後,系統table都改用InnoDB了。官方也建議沒有特殊需求的話,都用InnoDB
MySQL的Covering index
假設有這樣一張資料表有下面幾個欄位:
- id(PK)
- name
- age
- grade年級
- class班級 然後建立一個table_idx1是由grade和class組成
上面說到,除了PK其他索引都是secondary index,那這個table的secondary index的key就是由grade和class組成,葉節點資料就會包含id
當我用這個SQL statement查詢的時候:
1SELECT id, grade, class WHERE grade = 'xxx' AND class = 'yyy'
使用這個secondary index就能得到所有需要的資料id, grade, class,我就不用再找clustered index了,這就是covering index
PostgreSQL的B tree Index
PostgreSQL的索引稱為B tree index,沒有明確說他們使用b tree還是b + tree,但看文件描述感覺應該是b + tree,也可以看看這篇SO的討論B+ tree or B-tree
在PG,所有B tree的index都是secondary index
而index tuple儲存指向record資料(heap tuple)的位置TID(block, offset)
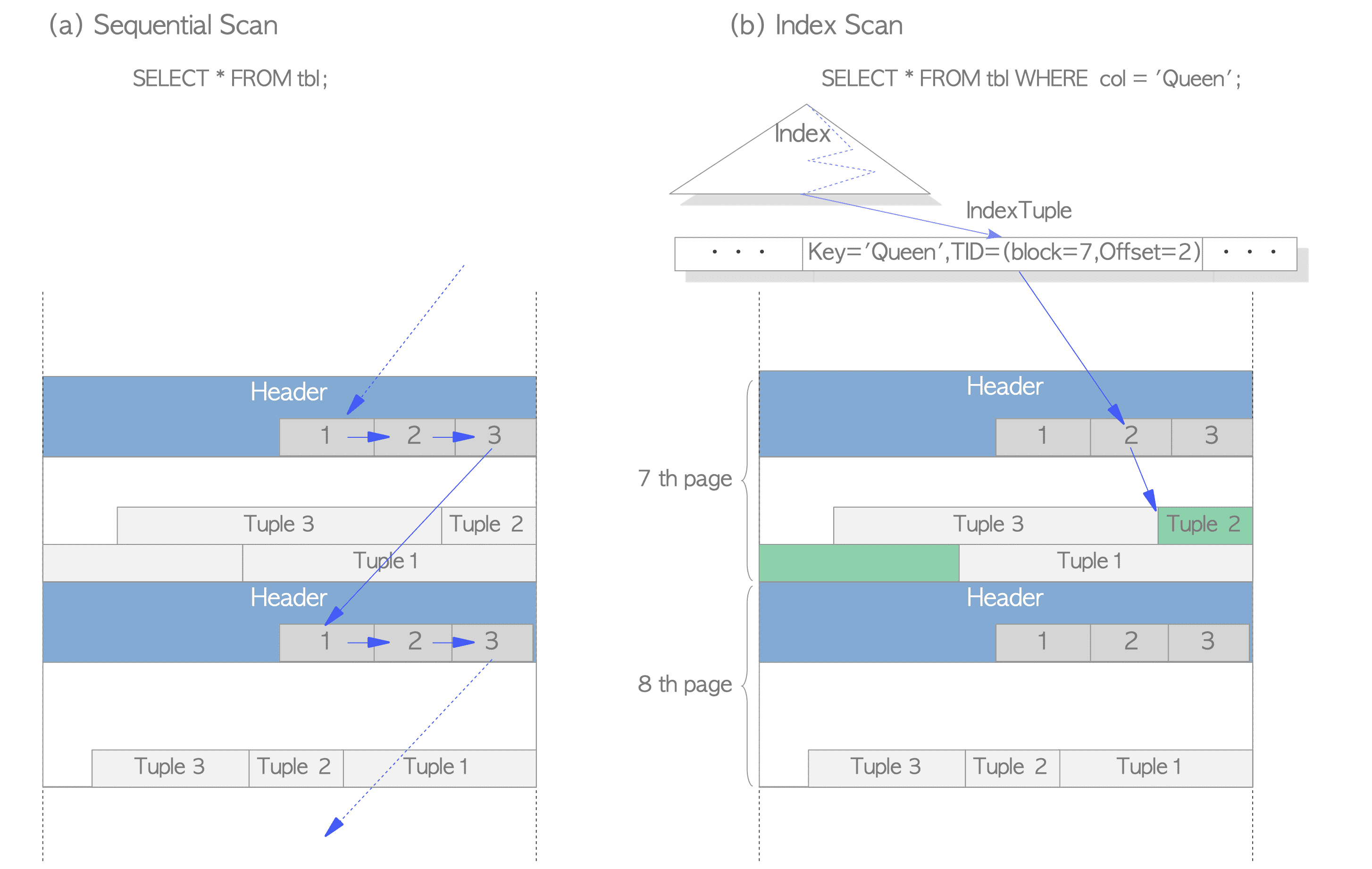
上圖右側的資料表,他的index是col,當沿著索引找到col = Queen的資料時,看到record資料位於第7個page的第2個itemId指向的tuple,那我們就可以去這裡查找
PostgreSQL的Index-only scan
先講解一下什麼是visible。一個record的visible對不同transcation來說是不一樣的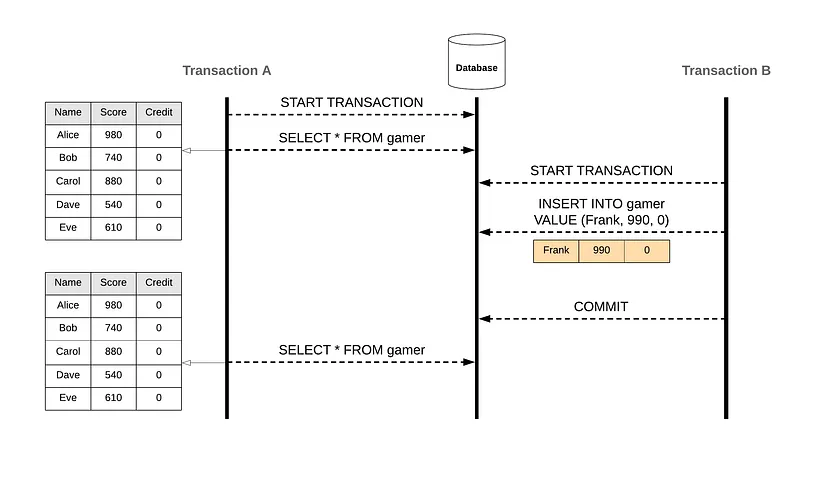
舉個例子,上圖中,當我A transaction取得整個資料表的資料,假設是5筆資料,這時B transaction就插入了一筆資料並且commit,之後A transaction再次取得整個資料表會拿到幾筆資料呢?
答案是5筆。因為當transaction開始會對讀取到的資料snap shot,之後讀取都是讀這個snap shot。所以對A transaction來說,第六筆資料就是invisible。當然這要視資料庫的isolation level隔離級別而定
回看PG的index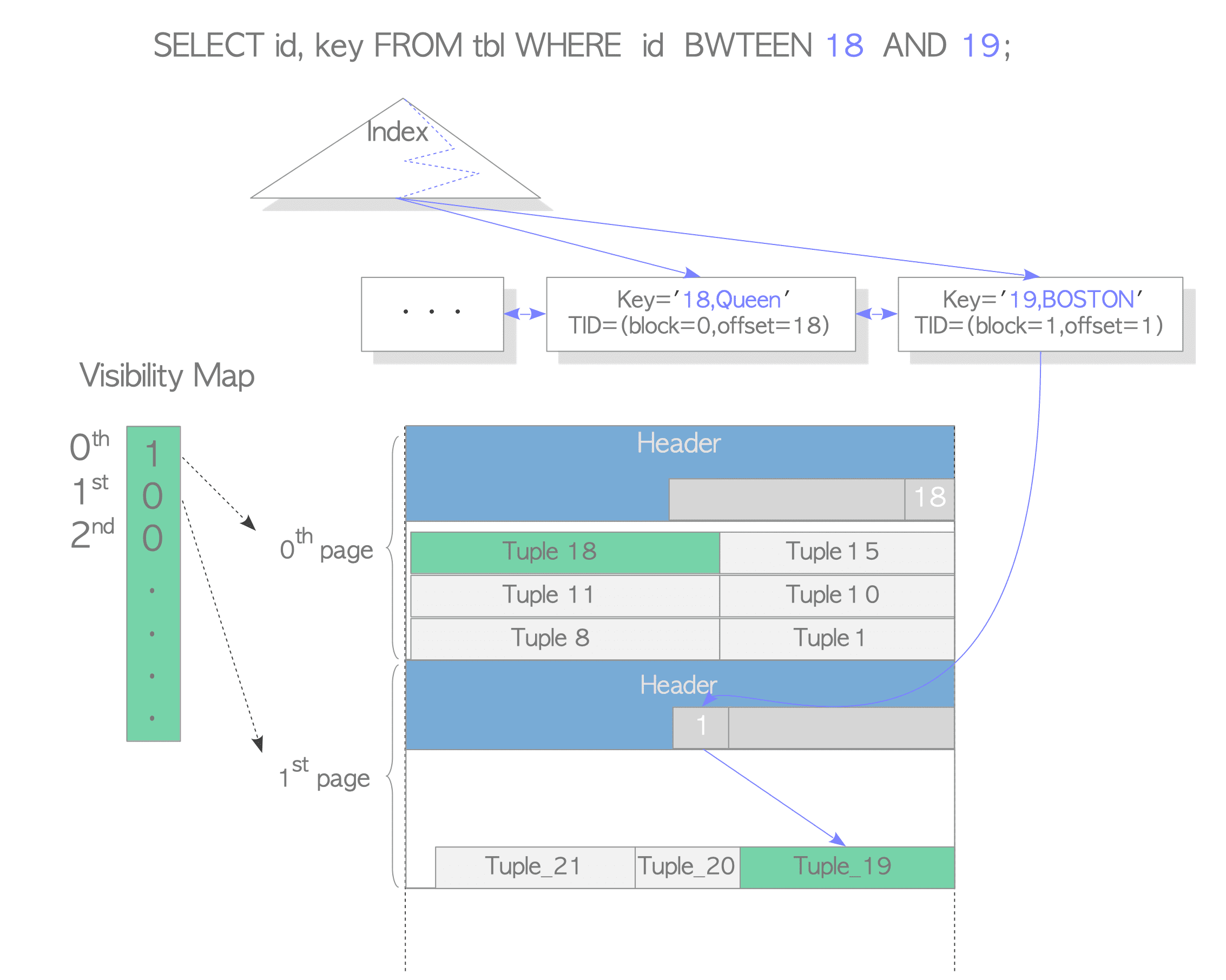
在PostgreSQL,資料的visibility都是存在heap tuple而不是index tuple裡面。所以就像前面提到的,找完index都要根據block和offset找heap tuple。這時配合visibility map就可以依情況避免。1表示這個page的所有tuple都是visible,可以不用查找heap tuple
第二種方法是建立covering index
1CREATE INDEX tab_x_y ON tab(x) INCLUDE (y);
建立一個索引是x欄位,但又包含y欄位,這樣我只要找x和y欄位時,就不用再去找heap tuple了
這個方法我還沒用過,有興趣可以參考COSCUP 2023 的一期影片PostgreSQL Index 的一些探討